type Raft struct { mu sync.Mutex // Lock to protect shared access to this peer's state peers []*labrpc.ClientEnd // RPC end points of all peers persister *tester.Persister // Object to hold this peer's persisted state me int// this peer's index into peers[] dead int32// set by Kill()
currentTerm int heartbeat bool// 用于标识上个 Election timeout 的期间内是否收到 heartbeat leaderId int32// 保存 leader id votedFor int votes int// 记录票数 log []LogEntry
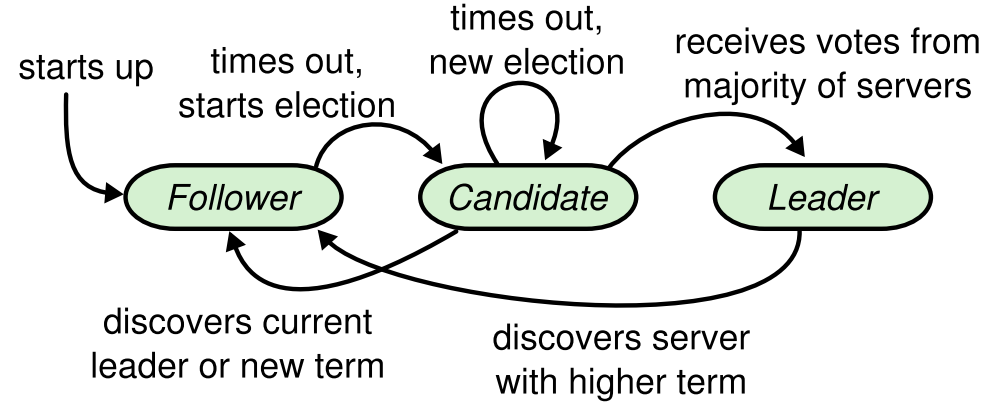
func(rf *Raft) ticker() { for !rf.killed() { if rf.noHeartbeat() { go rf.startElection() }
rf.mu.Lock() rf.heartbeat = false// 不管有没有超时,都直接让这一周期暂无 heartbeat rf.mu.Unlock() // pause for a random amount of time between 50 and 350 // milliseconds. ms := 50 + (rand.Int63() % 300) time.Sleep(time.Duration(ms) * time.Millisecond) } }
for i := range rf.peers { if i != rf.me { go rf.callSendRequestVote(i, args) } }
go rf.checkElection() }
func(rf *Raft) checkElection() { // save the current term // if the term changes, indicating that either // a leader has been elected or a new election // has started, return // otherwise, if votes > n/2, become leader // else return rf.mu.Lock() electionTerm := rf.currentTerm rf.mu.Unlock()
for !rf.killed() { // check if election timeout or a leader has been elected rf.mu.Lock() if electionTerm != rf.currentTerm || rf.leaderId != -1 { rf.mu.Unlock() return } // if won the election if rf.votes > len(rf.peers)/2 { rf.mu.Unlock() go rf.startAsLeader() break } rf.mu.Unlock() time.Sleep(10 * time.Millisecond) } }
需要注意的地方
在第一次通过测试后,出现了 “warning: term changed even though there were no failures”. 后面发现,在实现中我通过 rf.heartbeat 来判断过去一个任期内是否有心跳,但是在发送心跳的代码中没有给 leader 自己设置这个位置,导致了 leader 自己也会选举超时。
for !rf.killed() { rf.mu.Lock() if rf.currentTerm != term { rf.mu.Unlock() return } // 这个地方出问题了 rf.heartbeat = true rf.mu.Unlock() for i := range rf.peers { if i != rf.me { rf.callSendHeartbeat(i, args) } } time.Sleep(10 * time.Millisecond) } }