Consistent-Teacher: 代码阅读
本文最后更新于 2024年3月13日 上午
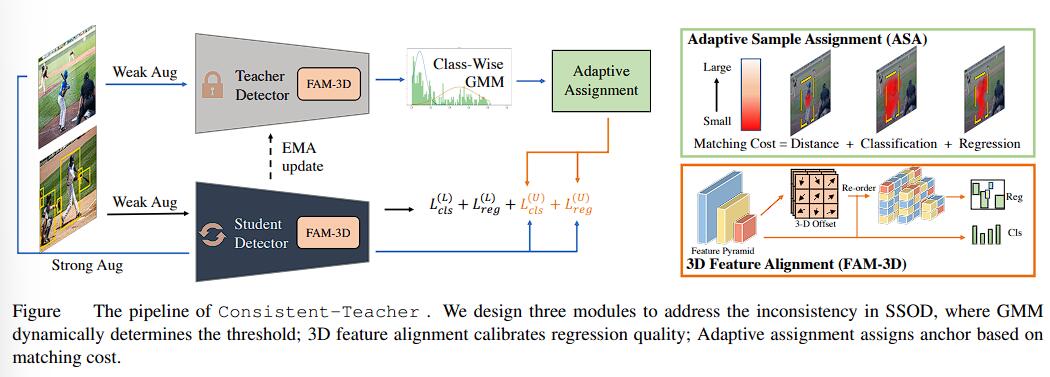
本文是 Consistent-Teacher 半监督学习框架的源代码阅读。论文详情可以参考上一篇文章。
Consistent Teacher 的代码是基于 MMDetection 实现的。官方仓库中标注的文件结构如下:
1 | |
先来看看 configs/consistent-teacher/consistent_teacher_r50_fpn_coco_180k_10p_2x8.py,也就是 Consistent-Teacher 半监督框架下,使用 ResNet50 作为 Backbone,FPN 作为 Head,使用 10% 的 COCO 数据集在 8 张 GPU 上每个 GPU 输入两张图进行训练的配置文件。
配置
第 1-6 行注明了继承的基础配置文件。不过本质上就是标注了使用 COCO 数据集,以及基础的 scheduler 和运行时环境,没有什么特别好说明的。
Detector 配置
第 8-64 行注明了 Detector 的配置,主要对应的还是 RetinaNet 的具体结构。修改的部分主要只有 FPN 连接的 FAM-3D 对特征金字塔进行重排后再进行分类和 bbox 的回归任务。
1 | |
有标签数据的训练数据流
69-119 行定义的 train_pipeline 对应了数据用于训练时的读取与预处理配置。
1 | |
用于测试的数据流则比较简单:
1 | |
无标签数据的弱增强与强增强数据流
配置文件中弱增强与强增强分别对应了两条 pipeline:weak_pipeline 与 strong_pipeline。弱增强的图像用于无标注图像在教师模型上的推理与有标注图像在学生模型上的训练,强增强的无标注图像用于学生模型对于图像在教师模型上的生成的伪标签进行训练。
weak_pipeline 的配置如下。主要是做缩放、翻转等简单的数据增强。
1 | |
strong_pipeline 的配置如下。主要做了缩放、翻转、旋转、颜色、亮度变化等较为复杂的数据增强。
1 | |
后续,对于两种不同程度增强的数据流,配置文件中使用了 MultiBranch 多路数据流进行整合,构成了无监督信号的数据流 unsup_pipeline。
1 | |
原始论文中应该是要把强增强的图像给学生的,但是不知道为什么这里写反了(
同框架下 Soft Teacher 中数据流与与论文中一致:
1 | |
半监督框架配置
配置文件的 297-308 行的 semi_wrapper 配置了所使用的半监督学习框架以及训练配置。
1 | |
这个 wrapper 在 ssod/utils/patch.py 76-78 行中调用,直接将配置文件的模型替换为 semi_wrapper 以被 MMDetection 实例化进行训练。
ConsistentTeacher 类
ConsistentTeacher 继承了 MultiStreamDetector,先来看看这个类。
1 | |
MultistreamDetector 继承了 BaseDetector 类,从构造函数中可以看出来就是将传入的模型字典 model 设置为 (model_name, model) 的类 attributes. model(**kwargs) 返回传入的参数字典中的 submodule. freeze(model_ref) 则将模型名对应的模型参数冻结不再更新。
接下来看 ConsistentTeacher 类的构造函数。
1 | |
首先注意到对于类,代码中使用了 @DETECTORS.register_module() 以注册自定义检测器使该检测器能够被 MMDetection 的配置文件识别。
构造函数中传入模型字典,使用父类 MultiStreamDetector 构造函数进行初始化,分别传入 teacher 和 student 模型,并且延用相同的训练、测试配置文件。
然后是 forward_train()。这个函数主要定义了教师模型和学生模型的检测器在训练中 forward 的具体行为。
1 | |
forward_unsup_train() (这里原本论文的函数命名又又又有 typo,原本名字是 foward_unsup_train)主要定义了无监督训练的高阶抽象过程。
1 | |
接下来分别看 extract_teacher_info() 和 extract_student_info()。
extract_teachder_info() 是教师的 pipeline.
1 | |
学生的检测框与标签生成就简单许多。
1 | |
最后看看 GMM 策略的具体实现。gmm_policy() 定义了 GMM 策略。分为以下三步:
- 使用预测 bbox 来拟合有两个中心(对应的是能否被选为伪标签)
- 找到最接近 GMM 中 postive 分布的 bbox
- 使用该分类置信度作为 GT 的阈值
1 | |
ConsistentTeacher 类的代码到这里就基本结束了。这个部分主要使用 FAM-3D 的 ImprovedRetinaNet 和 GMM 边框阈值策略进行伪 GT 筛选。
FAM3D 类
DynamicSoftLabelAssigner 类
(未完待续)