Consistent-Teacher: 减少半监督对象检测中不一致的伪目标
本文最后更新于 2025年9月16日 上午
Introduction
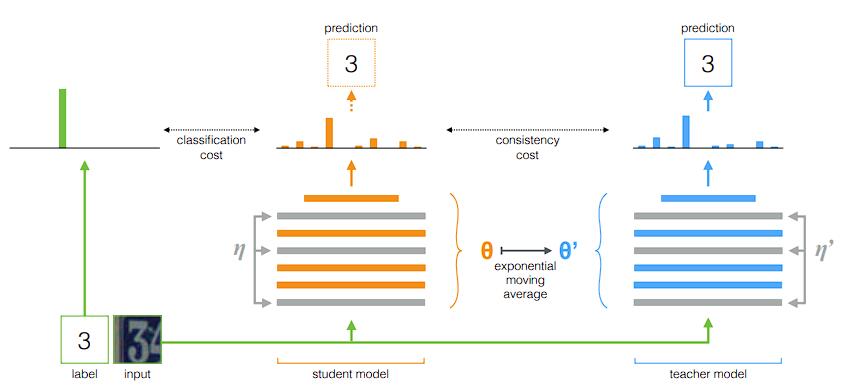
通常实现半监督目标检测是在老师模型上使用有标注的数据进行训练,然后用老师模型对未标注的数据集生成伪标签和边框,利用这些伪标签和边框作为学生模型的 ground truth. 学生模型则需要在无论是否存在网络随机性 (stochasticity) 和数据增强的前提下对数据进行一致的预测。为了提升伪标签质量,老师模型通常会使用学生模型权重的 moving average 来更新自身的权重。
本文认为半监督检测器的性能因为伪目标(标签+边框)的不一致性 (Inconsistency) 受到很大的阻碍。不一致性意味着伪边框可能很不精确,并且在训练的不同阶段变化很大。因此 bounding box (bbox) 的震荡让 SSOD 预测结果具有积累性的错误偏移。
本文发现分类和回归任务的不匹配是引起伪标签漂移的重要因素。通常过滤 SSOD 问题中的伪 bbox 只使用分类得分 (classification score). 但是置信度不能体现 bbox 的质量。图2 体现了当锚点一致的情况下 bbox 与 GT 存在较大差距引起伪标签漂移的现象。
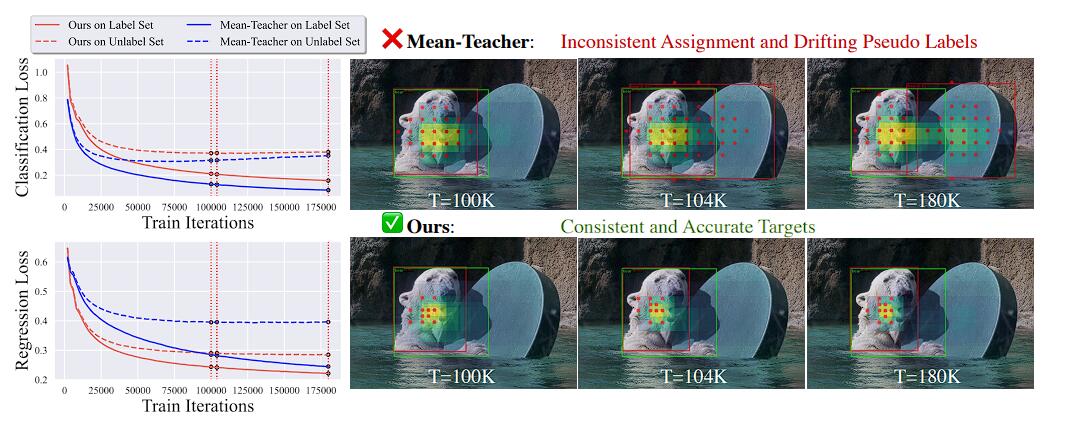
同样的,目前广泛使用的硬阈值策略同样引起了伪标签不一致的问题。传统 SSOD 方法使用静态阈值作为筛选作为伪标签的置信度,然而阈值需要动态调整。
本文提出了 Consistent-Teacher 方法来改进不一致性的问题。具体来说:
- 将静态的基于 IoU 的 anchor assignment 替换成 cost-aware adaptive sample assignment, 减轻了伪目标很密时的不一致影响。具体来说,计算匹配学生模型预测与伪标签匹配的 cost, 选择一些 cost 最小的预测。这样能够减少学生和老师间的错误匹配问题,减少了过拟合。
- 校准分类和回归任务,使得老师的置信度更能代表 bbox 的质量。文本提出了 3D 特征对齐模块 (FAM-3D),使得分类特征能够为回归任务探知和适应最佳的相邻特征(这里原文是 feature in its neighborhood)。
- 使用 GMM 来生成自适应的阈值,来解决阈值不一致的问题。将每个类的置信度作为正负分布的参数(?)使用最大似然方法估计混合高斯模型中高斯分布组成的参数。
Consistent-Teacher
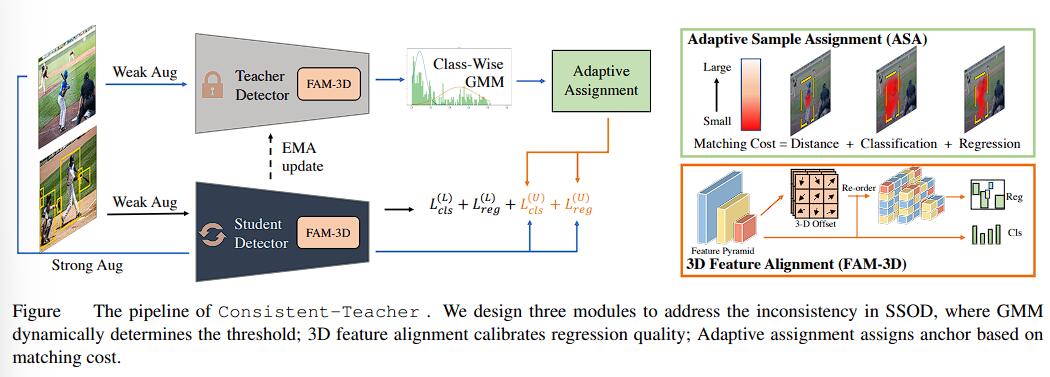
Consistent-Teacher 主要由三个关键部分组成:
- Adapative Sample Assignment
- 3D Feature Asignment Module
- Gaussian Mixture-based Thresholding
Baseline
Mean Teacher 作为本文的 baseline. 未标注的数据线经过弱增强,然后给老师模型来生成伪 bbox. 伪 bbox 后续被用作学生网络(通常未标注数据的图像抖动很剧烈)的监督信号。
与此同时,学生检测器使用标注的图像作为输入学习分类和回归的辨别式表示(注意对于目标检测问题,在提出 proposal 后需要对边界进行回归,使得边界更加接近 GT, 后续进行分类)。
Consistent Adaptive Sample Assignment
对于 RetinaNet 中的锚点,只有当与 GT bbox 的 IoU 超过一定阈值的时候才为 positive 的。这样静态的标签分配破坏了半监督学习中非常重要的一个特性。
以分类问题为例,实体级别的伪标签应该满足:
$$
\hat{c} = \underset{c}{\text{argmin }} \mathcal{L}(f_t(\mathbf{x}^u), c)
$$
这表示一个伪标签应该与自己的预测对齐。但是,这点在 SSOD 背景下使用静态锚点分配的时候被破坏了。这是因为标签有的时候会与自己的预测相冲突,这也是伪标签偏移现象的原因。
因此本文提出,应该把伪 bbox 分配给最小化自我损失的锚点:
$$
\min_{a_1, \dots, a_N} \sum_n^N \left[\mathcal{L} _{cls}(f_s(\mathbf{x} ^u), \hat{\mathbf{y}} _{a_n}^u) + \mathcal{L} _{reg}(f_s(\mathbf{x} ^u)_n, \hat{\mathbf{y}} _{a_n}^u) \right]
$$
其中,$n$ 为锚点下标,$a_n \in \{1, 2, \cdots, L+1\}$ 代表 $L$ 个预测的标签,$L+1$ 为背景标签。
一个简单的解决办法就是直接将一个锚点分配给伪 bbox.
BBox Consistency via 3D Feature Alignment
注意到常规的 SSOD 框架中伪 bbox 单纯是根据分类得分(分类置信度?)生成的,然而这并不能代表伪 bbox 在位置上的正确性。
本文推出了 3D Freature Alignment Module (FAM-3D) 来结合 bbox 的位置和分类置信度,允许分类特征适应性地用于回归任务地最优特征。(这是不是就是注意力机制…)
假设特征金字塔是 $\mathbf{P}$, $P(i,j,l)$ 意味着在第 $l$ 层,空间位置为 $(i, j)$. 我们想要构造一个重采样的函数 $\mathbf{P}’ \leftarrow s(\mathbf{P})$ 来重新排列特征图来进行回归任务。所以说 $\mathbf{P}’$ 最好要与分类特征对齐。
如图三中所示,本文添加了一个额外的 $\text{CONV} _{3\times 3}(\text{RELU}(\text{CONV} _{1\times 1}))$ 层在不同的 FPN (特征金字塔网络) 层中,并且对于每一个预测估计一个偏移向量 $\mathbf{d} = (d_0, d_1, d_2)$. 后续 $\mathbf{P}$ 被以如下方式重新排序:
$$
\begin{aligned}
P’(i, j, l) &\leftarrow P(i+d_0, j+d_1, l) \\
P’(i, j, l) &\leftarrow P(i’, j’, l+d_2)
\end{aligned}
$$
其中,第一行是用来调整 2D 空间中的特征偏移,而第三行则是在金字塔的不同 scale 中调整。
Thresholding with Gaussian Mixture Model
我们假设对于一个分类 $c$ 在没有标注的数据集上的预测得分是从一个高斯混合模型 (GMM) $\mathcal{P}(s^c)$ 中采样得到的,且所有未标记数据只有两种情况,positive 或者 negative. 那么对于这个 GMM, 我们有:
$$
\mathcal{P}(s^c)=w_n^c\mathcal{N}(s^c|\mu_n^c,(\sigma_n^c)^2)+w_p^c\mathcal{N}(s^c|\mu_p^c,(\sigma_p^c)^2)
$$
其中 $w_n^c, w_p^c$ 为 positive 或者 negative 的权重。那么 EM 算法就能够用来估计先验分布 $\mathcal{P}(pos|s^c, \mu_p^c, (\sigma_p^c)^2)$. 那么自适应的置信度阈值就可以以如下式子决定:
$$
\tau^c=\underset{s^c}{\text{argmax }} \mathcal{P}(pos|s^c, \mu_p^c, (\sigma_p^c)^2)
$$
在实际应用中,我们会为每个分类维护一个大小为 $N$ (~100) 的预测队列来拟合 GMM. 只有 $K=\sum _{k} (s_k)$ 个预测能够被存在队列中。
Expriment
该论文的代码在 GitHub 仓库 开源,使用 mmdetection 框架编写。