A brief introduction to weakly supervised learning - 阅读笔记
本文最后更新于 2025年7月11日 下午
本文是周志华在 National Science Review 上发表的文章 “A brief introduction to weakly supervised learning” 的简单阅读笔记(虽然现在看起来更像节选翻译),当作厕所读物即可,图一乐。此外本文会比较详细介绍半监督学习的部分,而其他的部分则会简单带过。
介绍
机器学习算法在监督学习的任务下已经取得了成功,而弱监督学习的需求近年来也越来越高。
为什么需要弱监督学习?
对于许多深度学习算法,模型都是从大量的训练数据中学习参数。典型的数据样例可以表示为 (特征, 标签),其中特征描述了一个物体的,而一个标签代表着 ground truth。在典型的分类问题中,ground truth 代表了这个物体属于哪个分类。
然而在现实是,有标签的训练数据并不是那么好获得的。比如在医学场景中,不可能将大量病灶的图像交给医生进行标注(毕竟画框框和打分类标签真的挺麻烦的)。此时模型从没有标记的数据中进行学习变得非常重要,这就是弱监督学习(的一部分)的意义所在。
弱监督学习的分类
常见的弱监督学习分成三类:
- Incomplete supervison: 只有小部分训练数据有标注
- Inexact supervison: 标注是粗粒度的。例如,只知道一个图像里有个什么东西,但是不知道其确切位置
- Inaccurate supervison: 有的时候标注是错的
本文仅会对这三种情况分别讨论,但注意在实际中这三种情况可能同时出现(悲)。
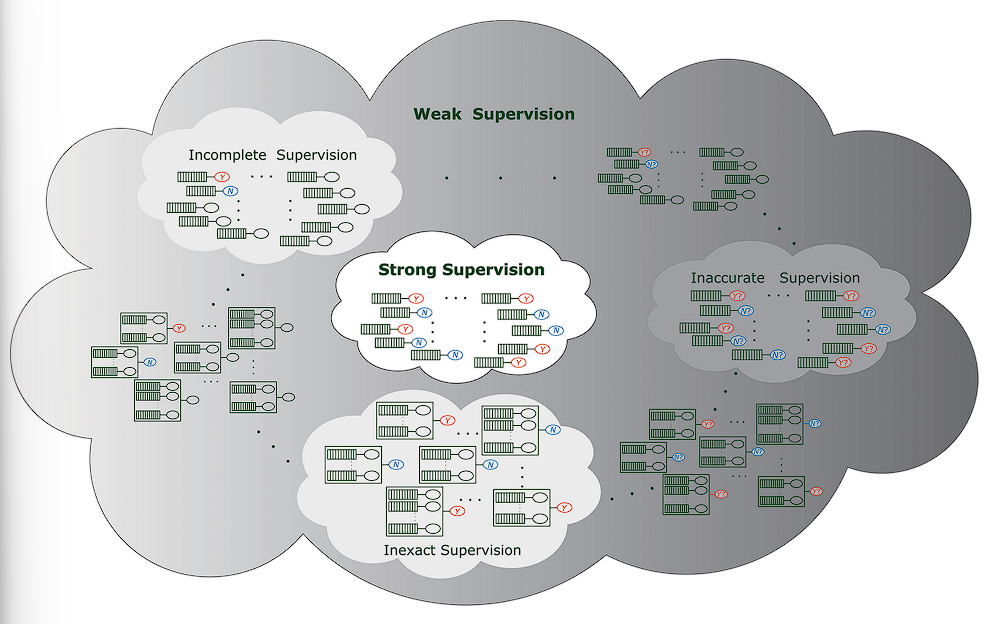
强监督学习与数据集假设
为了简单起见,本文仅会考虑 Yes or No 的二分类情况。
形式化的,在强监督下,监督学习的任务是从训练集 $D = { (x_1, y_1),
\dots, (x_m, y_m)}$ 中学习函数 $f: \mathcal{X} \mapsto \mathcal{Y}$。其中 $\mathcal{X}$ 为特征空间,$\mathcal{Y} = {Y, N}$,$x_i\in \mathcal{X}$,$y_i\in \mathcal{Y}$.
对于这个数据集,我们有一个假设:$(x_i, y_i)$ 都是从一个未知的、独立的、唯一的分布 $\mathcal{D}$ 中生成的。换句话说 $(x_i, y_i)$ 具有独立同分布假设。很多统计学上成立的东西都需要在依赖于这个假设。
不完全监督 (Incomplete Supervision)
对于不完全监督的任务,我们关心的是只有少量标注数据,并且不足以训练一个好的模型的情况。
形式化的,从训练集 $D = {(x_1, y_1), \dots, (x_l, y_l), x_{l+1}, \dots, x_m}$,从中学习函数 $f: \mathcal{X} \mapsto \mathcal{Y}$。其中 $l$ 为有标注的样本数量,$u = m-l$ 为无标注的样本数量。
对于不完全监督学习的任务,主要有两种主要的技术
Active learning: 主动学习
主动学习假设存在 “orcale” 可以帮助机器学习,例如一个人类专家。机器可以向专家询问来得到未标注实体的 ground truth.Semi-supervised learning: 半监督学习
半监督学习倾向于不依赖人类介入自动利用未标注的数据,让它成为标注数据,来改善学习效果。半监督学习也分成两类:**(pure) semi-supervised learning** 和 transductive learning (直推学习). 前者认为未标记的数据也是训练数据。而后者认为未标记的数据实际上就是测试数据,从而利用测试数据来改善模型在测试数据上的表现。通常情况下直推学习的效果要比归纳学习的效果要好,因为直推学习可以利用未标注的数据来增强模型在测试集上的泛化。
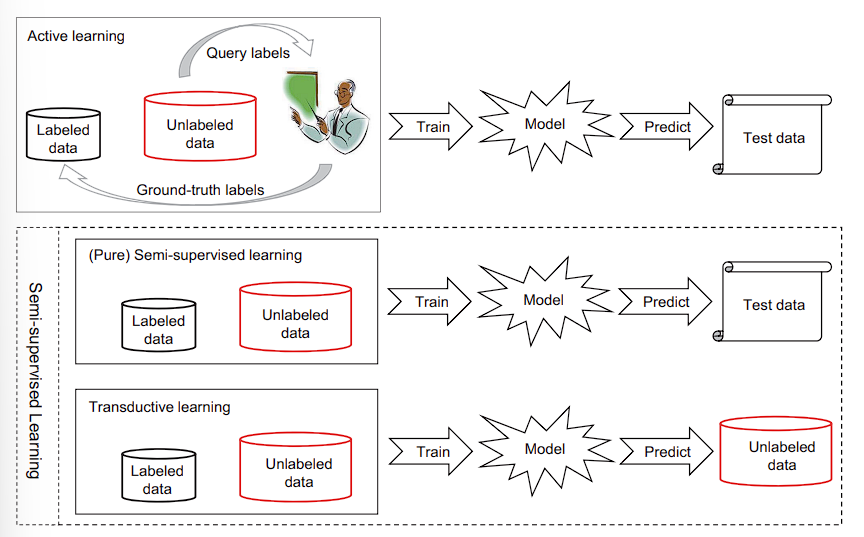
有人类介入 (Active learning)
主动学习方法倾向于选取最有价值的无标注实体进行询问。现在有两种广泛使用的选择标准:
- Informativeness: 信息量。衡量一个未标注实体能够减少模型不确定性的程度。
- Representativeness: 代表性。衡量一个实体能够帮助代表输入模式 (input pattern) 的程度。
基于信息量的方法
基于信息量的方法主要有两种:Uncertainty sampling (不确定性采样) 和 query-by-committee (投票询问)。前者只训练一个模型,询问 confidence 最低的实体;后者生成多个模型,对模型最不同意的实体进行询问。
基于代表性的方法
基于代表性的方法通常希望利用未标记数据的聚类结构进行询问,一般使用聚类方法。
弱点?
基于信息量的方法的主要弱点在于,它们严重依赖于有标注数据来构建最初的模型,所以在有标注数据较少的情况下通常表现非常不稳定。而基于代表性的方法的主要弱点在于未标注数据决定了聚类结果,尤其是只有少量未标注数据的时候。因此近期的主动学习方法主要尝试结合结合信息量和代表性。
无人类介入 (Semi-supervised learning)
半监督学习不依赖人类,自动利用未标注的数据。
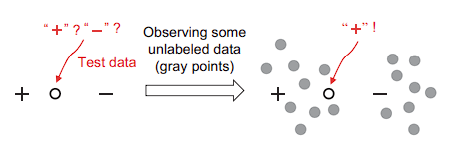
那么如何根据未标注数据来学习呢?文章中举了一个简单的例子。
假设数据都是从含有 $n$ 个高斯分布的高斯混合模型中获得的,也就是说
$$
\begin{equation}
f(\mathbf{x} |\Theta) = \sum_{j=1}^n \alpha_j f(\mathbf{x} |\theta _j)
\end{equation}
$$
其中
- $\alpha_i$ 为混合参数 (mixture coefficient), 且满足 $\sum_{i=1}^j \alpha_i = 1$
- $\Theta = {\theta_i}$ 为模型参数
在这个情况下 $y_i$ 可以看作是从分布 $P(y_i|\mathbf{x} _i, g_i)$ 中得到的随机变量。其中 $g_i$ 为混合成分 (mixture component), $\mathbf{x} _i$ 为特征向量 (feature vector). 根据 MAP,即最大后验估计,对于模型我们有:
$$
\begin{equation}
h(\mathbf{x}) = \arg \max_{c\in \{Y, N\}} \sum_{j=1}^n P(y_i = c | g_i = j, \mathbf{x} _i) \times P(g_i=j | \mathbf{x} _i)
\end{equation}
$$
其中
$$
\begin{equation}
P(g_i=j | \mathbf{x} _i) = \frac{\alpha_j f(\mathbf{x}_i|\theta_j)}{\sum _{k=1}^n \alpha_k f(\mathbf{x}_i | \theta_k)}
\end{equation}
$$
对于上式中的各项比较好解释。对于模型我们其实就是找到一个对于二元分类 Y/N 最有可能,即最大概率的类型。$P(g_i=j | \mathbf{x} _i)$ 项则为特征向量来自高斯混合模型中某个组成的概率,$P(y_i | \mathbf{x} _i)$ 则为这跟个组成中 $y_i=c$ 的概率。于是乘起来加权平均后就是 $P(y=c|x_i)$,接着取最大值就可以知道 $x_i$ 对应的 $y$。
对于一个模型的估计我们可以分成两个部分:需要标注的 $P(y_i=c | g_i=j, \mathbf{x} _i)$ 和不需要标注的 $P(g_i=j | \mathbf{x_i})$,于是我们可以通过无标注数据学习后者来改进模型表现。
聚类假设与流形假设
实际上半监督学习有两个基本的假设:聚类假设与流形假设。这两个假设都是关于数据分布的。
前者认为数据有与生俱来的簇 (cluster) 结构,因此在同一个簇内的实体具有相同的类标签。后者认为数据分布在一个流形上,同样的,邻近的实体具有相似的预测。
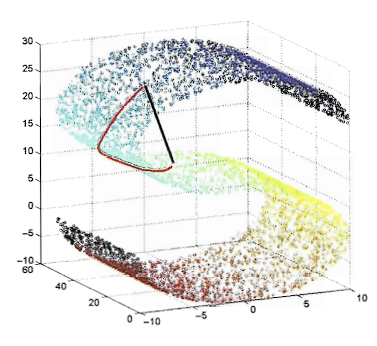
这两种假设的本质都是认为相似的数据点应该具有相似的输出,从而让未标注数据帮助判断哪些数据点是相似的。
半监督学习方法
半监督学习方法有四种主要的途径:
- Generative methods: 生成式方法
- Graph-based methods: 基于图的方法
- Low-density separation methods: 低密度分割方法
- Disagreement-based methods: 基于拒绝的方法
生成式方法假设有标注的数据和无标注的数据都是从相同的与生俱来的模型中生成的。因此无标注的数据可以被当作是缺少值的模型参数,可以被 EM (Expecetation-maximization) 算法估计。为了获得良好的表现,使用此类方法需要对数据具有足够好的领域专业知识来决定一个合适的生成式模型。同样这个领域也有尝试结合生成式模型和判别式模型的优势的方法。
基于图的方法构造一张图,其中节点对应着训练数据,而边对应着数据间的关联(通常是相似度或者距离),然后通过某种标准将标签信息在图上传播,例如:标签可以在被最小割分开的子图中传播。目前这类方法的表现严重取决于图是如何构造的,同时由于时空复杂度的关系,这种方法无法大规模使用。此外,因为很难将新的数据添加到图上,这种方法也没有办法使用直推学习。
低密度分割方法强制让分类边界穿过输入空间的低密度区域。最著名的代表为 S3VM (semi-supervised support vector machines).
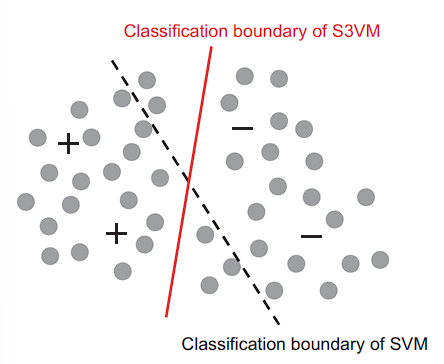
基于拒绝的方法生成多个学习者,让他们合作利用未标记的数据。而学习者之间的“不同意见”对于学习过程至关重要。最著名的代表,联合训练 (co-training), 让两个学习者从两个不同的特征集合中学习。在每一个循环中,每个学习者挑选置信度最高的无标注实体,将预测值作为伪标签 (pseudo-lable) 作为另外一个学习者的训练样本。这样的方法可以通过进一步组合学习者作为 ensemble learning. 注意这个方法可以被应用在主动学习中,当学习者全部具有低置信度或者具有高置信度但是意见不统一的情况,可以将实体进行询问。
其中基于拒绝的方法在目前的半监督学习研究中极为广泛。著名的 Mean Teacher 模型就是基于该方法。
不精确监督 (Inexact Supervision)
不精确监督关心问题是,一些监督信号不如我们所预想的一样精确。一个经典的情况就是,我们只能得到粗粒度的标签信息。举个例子,在药物活性预测中,我们的目标是构建一个模型学习已知的分子结构来判断一个分子是否能够被制作成一种特殊的药品。即使是对于已知的分子,人类专家也只知道分子是否是合格的,而不知道什么样特殊的结构是决定性的。
形式化地,Inexact Supervision 的任务是从训练数据集 $D=\{(X_1, y_1), \dots, (X_m, y_m)\}$ 中学习函数 $f: \mathcal X \mapsto \mathcal Y$. 其中 $X_i = \{\mathbf{x} _{i1}, \dots, \mathbf{x} _{i, m_i}\} \subset \mathcal{X}$ 被称为一个包 (bag).
而 $x_{ij} \in \mathcal{X} \quad (j \in \{1, \dots, m_i\})$ 被称为一个实体(instance),$m_i$ 为 $X_i$ 中的实体数量,$y_i \in \{Y, N\}$。当 $X_i$ 中存在 $\mathbf{x}_{ip}$ 为 positive 时且 $p\in \{1, \dots, m_i\}$ 未知时,$X_i$ 为一个 positive bag,也就是说 $y_i=Y$。
目标是预测从未见过的 bag 的标签。这被叫做 multi-instance learning.
目前许多研究者已经开发了许多高效的算法解决 multi-instance 问题,主要通过尝试以下方法:
- 将完全监督单实体学习算法的注意力转移到对于 bag 的判别上
- 通过表示转换(representation transformation)来使用单实体表示多实体
注意到实体通常被认为是独立同分布的,但是多实体学习不应该采取 IID 假设,尽管 bag 能够被认为是独立同分布的样本。在这个假设的基础上,许多高效的算法已经被开发出来。
与自然存在的 bag 不同,像是化学分子这样的 bag 需要通过 bag generator 生成。典型的,许多小的 “patch” 可以被图像中提取出来作为样本,而文本中也可以通过提取句子、词汇来生成 bag。尽管 bag generator 在学习的表现上有很重要的影响,在最近才有比较高效的图像 bag generator 被提出。

原本的 multi-instance 学习目标是预测从未见过的 bag,单现在有许多研究试图辨别使得一个 bag 为 positive 的关键实体。这些任务在没有细粒度训练数据时定位图像 RoI 上非常有帮助。
同样值得一提的是标准的 multi-instance 学习假设每一个包至少包含一个关键实体,但有些研究假设没有关系实体,并且每个实体对于 bag label 均有所贡献,甚至假设对于包的 positive 具有多重概念,并且仅当实体满足所有概念时包才能为 positive 的。
早期的理论结论证明了多实体学习在异构(就是说,包可以通过不同的规则判断 positive/negative)的情况下十分困难,而在同构(相同规则可以判断)的情况下是可以实现的。幸运的是,绝大多数实际中的多实体任务为同构类型。
不正确监督 (Inaccurate Supervision)
不准确监督关心的是监督信号不完全是 GT 的情况。换句话说,一些标签信息可能错误的。
一个典型的场景是学习携带有噪声的标签。目前已经有许多研究围绕着具有随机分类噪声的标签展开(就是说这些标签是噪声)。实践中,一个基础的想法是辨认可能被错误标注的样本,然后尝试做出一些修正。
数据编辑 (Data Editing)
举一个例子,一个数据编辑(data-editing)的方法是构造一个 relative neighborhood graph,其中每一个节点对应着一个训练样本,两个节点之间会有一条边相连。其中,连接着两个具有不同标签的边被称作切边(cut edge)。
直觉告诉我们,一个标注可能是错误的节点,会于许多切边相连。这个很可疑的实体可以被移除,或者被重新标注。
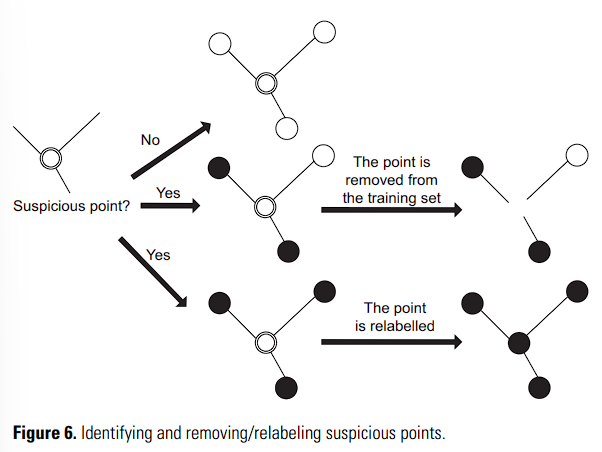
值得一提的是,这种基于相邻信息的方法在高维特征空间中会因为数据的稀疏性变得不可靠。
群众外包 (Crowdsouring)
另外一个有意思的场景是群众外包进行数据标注。在机器学习领域,群众外包通常是一个收集训练数据的省钱方法。
一个著名的群众外包标注系统,Amazon Machanical Turk (AMT),在这上面用户可以提交任务进行标注。在这些用户中,可能有一些会比其他的人更加值得信赖,然而,这些用户由于隐私保护通常不会被提前知道。同时还有可能存在一些人随机地进行标注,或者故意地给出一些错误的标注。有些任务可能对于用户来说太难了。
许多研究尝试从人群的标注中推导出 ground-truth。具有理论支持的基于集群学习的投票策略已经在实践中广泛运用,并且得到非常好的效果,因此也通常被用作 baseline。我们有的时候还期望用户的工作质量和任务难度能够被建模,能够通过给不同用户分配不同权重来实现更好的表现。
设计一个高效的群众外包协议是非常重要的。在一些学习中提到,用户在对自己所标注的标签不是很自信的时候,可以不进行标注。同样还有一种 “double or nothing” 的激励机制能够保证用户基于他们的自信程度进行诚实的标注。
从学习效果上改进
对于机器学习领域来说,群众外包仅仅是用于收集数据的方法,但是模型本身从中学习的质量比数据本身更为重要。
目前已经有许多研究尝试从 weak teacher 或者 crowd label 中学习,这与从具有标签噪声的数据中学习十分类似。
Reference
Zhi-Hua Zhou, A brief introduction to weakly supervised learning, National Science Review, Volume 5, Issue 1, January 2018, Pages 44–53, https://doi.org/10.1093/nsr/nwx106