手术视频场景下的五元器材-组织交互检测
本文最后更新于 2024年3月13日 上午
本文是对文章 Instrument-tissue Interaction Quintuple Detection in Surgery Video (第一阶段)的大致梳理。前两天大致了解了后续的课题续工作需要在该论文的第一阶段进行一些改进。
Introduction
手术辅助系统,即 CAS (Computer-assisted surgical systems) 能够基于医生对于手术场景的理解协助医生进行手术,有助于提升手术安全和质量。
手术流程的识别算法大致可以根据粒度 (granularity) 分成三种级别:
- 阶段 phase
- 步骤 step
- 活动 activity
其中阶段和步骤为粗粒度的工作流表示。
之前的工作主要关注于阶段的识别,能够通过优化手术室的管理增加手术效率。一个手术阶段包含了一系列的步骤。对于步骤的识别,Hashimoto 等人开发了在腹腔镜胃部袖状切除手术 (laparoscopic sleeve gastrectomy) 的识别算法。
然而粗粒度的识别不能提供一个详细的手术场景的描述,而细粒度的活动识别对于手术训练、手术技巧评估和自动生成手术报告具有重要的意义。
之前的工作主要定义动作为一系列的动作(action),这种定义忽视了活动的目标和主体。为了得到对于手术场景的更完整的理解,Nwoye 等人推出了一种直接预测 (instrument, tissue, action) 标签来描述手术场景中的活动。其他的工作关注于在了解到器材和目标的位置以及类型后,推理器材和组织的交互。
Islam 等人开发了一种基于图网络的方法来推理交互类型。这些工作关注于类型的识别,而缺少了对于手术器材和组织的位置识别。然而对于 CAS 来说,器材和组织的位置信息是非常重要的。
因此,一个详细的手术场景中的活动描述应该是一个包含组织、目标、位置以及它们之间的相对关系的多元组合。然而当前对于手术场景中的工作倾向于只描述这个组合的一部分。
在自然场景下,人-物体交互(Human-object interation, HOI)检测也是对于场景详细理解的一个基本问题。大部分 HOI 检测的工作使用相似的流水线:先使用一个预训练的对象识别网络,比如 Faster R-CNN 或者 Mask R-CNN 来定位人和物体,然后将人和物体配对,来预测他们之间的动作。然而手术场景下直接应用自然场景的 HOI 检测方法并不能得到预期的效果,原因如下:
- 器材和组织更难检测
在白内障手术中,有很多透明的组织,并且器材和组织间会相互遮挡。 - 动作的预测更加复杂
在 HOI 检测中,一个动作的主体总是人类,然而在手术场景中有许多的手术器材能成为动作的主体。
对于上述问题,可以从如下一些方面进行改进:
- 理解手术场景需要多元的、细粒度的活动描述,来检测器材-组织的交互。本篇文章中,对于一个器材-组织交互,我们表示为 (instrument bounding box, tissue bounding box, instrument class, tissue class, action class) 的五元组。
- 为了更好检测手术场景中的器材和组织,结合时间和空间上的位置信息,来定位器材和组织。
- 考虑器材和组织间的关系推理对于五元组的预测至关重要,使用图神经网络来学习这个关系。
Methodology
本文提出的 Quintuple Dection Network (QDNet) 使用了一个两阶段的策略:器材组织检测阶段和五元组预测阶段。第一阶段中使用了修改的 Faster R-CNN 以及一个时空注意力层 (spatiotemporal attention layer, STAL) 来检测器材和组织的 bouding box。第二阶段,这些生成的 bouding box 被用来提取 RoI (regions of interest) 特征,然后填充到基于图网络的五元组预测层 (graph-based quintuple prediction layer, GQPL) 来预测五元组。
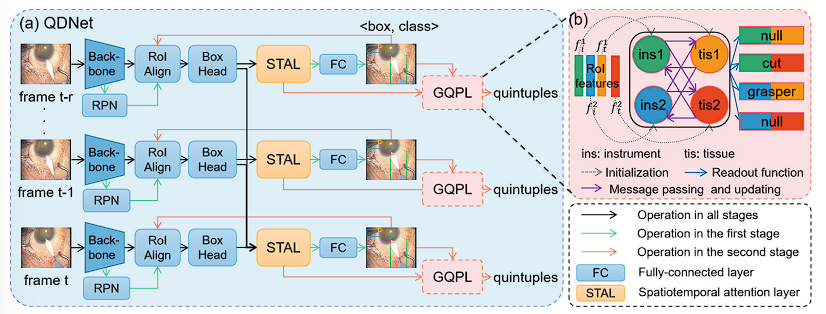
器材组织检测阶段
由于在手术场景中,器材经常被组织或者其他的器材遮挡;并且在一些手术中某些组织难以被检测,例如白内障手术中对于透明角膜的检测,直接应用 Faster R-CNN 不能提供理想的 RoI 特征。考虑到在标准化的手术流程中,器材和组织间存在特定的关系,本文建议结合帧之间的时间特征,以及组织和器材之间的空间特征来提高检测精确度。
如图1所示的 QDNet 结构,在 STAL 前为 Faster R-CNN 结构。
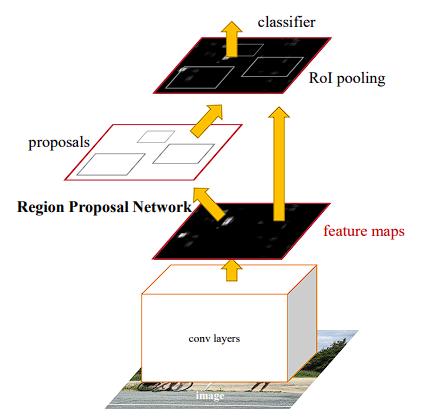
Backbone 网络(Faster R-CNN 论文中的卷积层部分?)对于每一个输入帧提取了特征图,接着一个 region proposal network (RPN) 根据特征图成 proposal 集合。RoI 对称网络和接着的 linear box heads (?) 提取了 proposal 区域的特征作为视觉特征 $f_v \in \mathbb{R}^c$,其中 $c$ 为特征维度。
为了提升检测精度,本文提出了 STAL 以适配相邻帧之间的器材和组织关系。Proposal 的视觉特征和空间位置特征被发送至 STAL 来获得时空的注意力特征。
对于这些 Proposal 的注意力特征,全连接层来预测 Proposal 属于的器材或者组织分类,并且通过回归修正 propsal 的边界。
本文在训练中采用了相同的 RPN Loss $\mathcal{L} _{rpn}$ 和 Fast R-CNN loss $\mathcal{L} _{rcnn}$。
时空注意力层 (STAL)
在标准化的手术流程中,手术器材和组织存在对应的关系,因为器材只能用在特定的组织上。这样的对应关系能够用来辅助器材和组织的检测。因为一个器材在空间上与一个目标组织靠的很近,空间信息可以用来为特征融合 (feature fusion) 提供引导。时间信息同时也能够为视频的检测任务提供帮助。
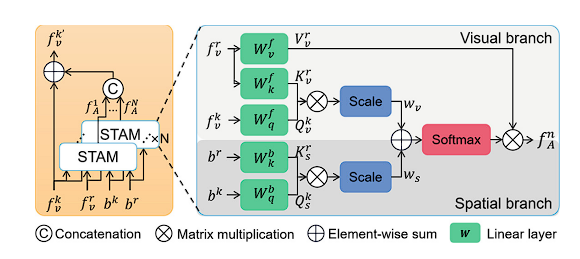
对于一个当前帧 $t$,我们把该帧当作关键帧,前 $r$ 帧当作参考帧 (reference frame)。STAL 从 $N$ 个时空注意力模块 (STAM) 聚合了 $N$ 个注意力特征,并且直接加上视觉特征,可以表示为
$$
\begin{equation}
f_v^{k’} = f^k_v + \text{Concat}(f_A^1, f_A^2, \dots, f_A^N)
\end{equation}
$$
其中 $f_A^n \in \mathbb{R}^{1\times c/N}$ 是第 $n$ 个 STAM 的输出特征,$f_v^k \in \mathbb{R} ^{1\times c}$ 是关键帧的视觉特征,$f_v^{k’} \in \mathbb{R}^{1\times c}$ 关键 STAL 完善的视觉特征输出。$\text{Concat}(\cdot)$ 是连接函数。
时空注意力模块 (STAM)
如图3所示,STAM包含了两个分支,一个视觉分支和一个空间分支。
视觉分支从关键帧 $f_v^k$ 和参考帧 $f_v^r$ 的 RoI 视觉特征中计算注意力生成视觉权重。$r$ 个参考帧中的 RoI 特征通过线性层映射成 key $K_v^r \in \mathbb{R} ^{r\times c/N}$ 和值 $V_v^r \in \mathbb{R} ^{r\times c / N}$.
空间分支从关键帧和参考帧的空间信息计算注意力,来生成空间位置权重。本文使用 binary box maps $b \in \mathbb{R} ^{h\times w}$ 来编码 RoI 的空间信息。若原始图像缩放后的大小为 $h\times w$,则 Binary box map 有 $h\times w$ 维,在 RoI 的位置为 1,在其他的位置为 0。Binary box 映射的关键帧 $b^k \in \mathbb{R} ^{1\times h\times w}$ 和参考帧 $b^r \in \mathbb{R} ^{r\times h\times w}$ 被修改大小,分别映射到 query $Q_s^k \in \mathbb{R} ^{1\times c / N}$ 和 key $K_s^r \in \mathbb{R} ^{r\times c / N}$。
接着,关键帧及其参考帧的 RoI 的视觉相似度权重 $w_v$ 和空间位置相似度权重 $w_s$ 可以被以下方式计算:
$$
\begin{equation}
w_v = \frac{Q^k_v {K_v^r} ^T}{\sqrt{d_v^r}}, \quad
w_s = \frac{Q^k_s {K_v^s} ^T}{\sqrt{d_s^r}}
\end{equation}
$$
其中 $d$ 为 $K$ 的维度。这两种权重用于聚合注意力权重。 STAM 的输出可以表示为:
$$
f_A^n = \text{softmax} (w_v+w_s)V_v^r
$$
五元组预测阶段
使用 GQPL 来为器材和组织之间的关系建模。器材和组织的局部特征被送进 GQPL 来提炼特征和进行五元组预测。训练中使用了 focal loss $\mathcal{L} _focal$。
由于该阶段与后续工作的关系不是很大,这里就不详细展开了。
Experiments
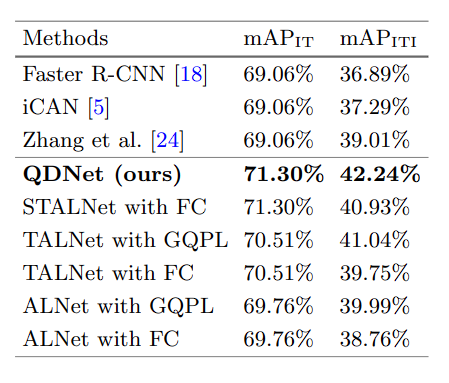
本文使用了基于 phacoemulsification 数据集,构建了 Cataract Quintuple Dataset。使用 mAP 作为 metric。为了验证 STAL 的有效性,mAP 同样用来衡量第一阶段中器材和组织的检测表现。我们记器材和组织检测的 mAP 为 $\text{mAP} _{\text{IT}}$,记器材组织交互五元组的 mAP 为 $\text{mAP} _{\text{ITI}}$。
Reference
Lin, Wenjun & Hu, Yan & Hao, Luoying & Zhou, Dan & Yang, Mingming & Fu, Huazhu & Chui, Cheekong & Liu, Jiang. (2022). Instrument-tissue Interaction Quintuple Detection in Surgery Videos. 10.1007/978-3-031-16449-1_38.